This section will first go through the optimizations you can make to your code and data to make it friendly to the Burst compiler. This will enable it to optimize your code better.
Preparing your project for Neon
In order to leverage Neon intrinsics in code, you first have to ensure that your project is using the Burst package.
Enable Burst package
In the Window menu, select Package Manager
Ensure that the Packages option in top left is set to Unity Registry
Search for burst
Select Burst from the list on the left
If Burst is already installed, it will be ticked. If not, select Install
Turn off ARMv7 architecture support
Neon intrinsics in Unity require ARMv8.
Select Project Settings from the Edit menu
Select Player from the list on the left
In the right-hand panel, scroll to Target Architectures under Other settings
Ensure ARMv7 is not ticked
Ensure ARMv8 is ticked
Allow unsafe code
We need to make use of memory pointers.
Remain in Player settings
Scroll to Script Compilation area
Enable Allow unsafe code
The Burst compiler
As you’ve already learned, the Burst compiler translates .NET bytecode to optimized native code. It is not applied across the whole of your project and there are some limitations as it doesn’t support all features of C#.
How is the Burst compiler used?
The Burst compiler can be used with the Job system or with static functions. The following is an example of a Burst Job:
using Unity.Burst;
using Unity.Jobs;
...
[BurstCompile]
struct MyJob : IJob
{
public void Execute()
{
... your code ...
}
}
Create your Burst Job based on IJob and write your code inside the Execute() function. The attribute, BurstCompile, tells Unity to use the Burst compiler.
Alternatively, you can use Burst static functions; that is, static functions tagged with the BurstCompile tag.
When running your app inside the Unity editor, your code will be compiled just-in-time (JIT). When built for your target platform, the code is compiled ahead-of-time (AOT).
Support for subset of C#
The Burst compiler only supports a subset of C# named High Performance C# . You should check the C# language support for the version of Burst you are using.
At the time of writing, the limitations included (but are not limited to) the following:
Exceptions may behave differently (in HPC# finally blocks are not called)
foreach and while are supported but you may get an error if the enclosing function has one or more generic collection parameters
catch is not supported
Methods related to managed objects, e.g., string is not supported
Some limitations may be removed over time as the Burst compiler is updated.
Why use the Burst compiler?
With minimal effort from the programmer, the Burst compiler is able to produce highly optimized native code that runs much faster. Part of this optimization is the ability to produce Neon native instructions. Neon instructions are great at processing multiple data items at once, i.e., processing multiple data items in parallel rather than one at a time (or scalar operations).
Auto-vectorization
Producing vector-based instructions from code is called vectorization. The Burst compiler is capable of auto-vectorizing code, i.e., the programmer doesn’t have to write Neon instructions. The compiler can do even better if we follow a few simple rules or best practices.
Best practices
The way data and code are structured are very important factors that will influence the compiler’s ability to auto-vectorize. Here are some recommended best practices:
Keep your code loops simple and small rather than large and complex
Where multiple data items are processed with the same operation, keep those data items together in contiguous memory (there are vector instructions for fetching, processing and saving multiple data items at once if they are in contiguous memory locations). This will also help cache efficiency.
Where the same operation is performed multiple times, try to keep those operations sequential in your code
Where possible, use fixed-length for loops (they are easier for the compiler than while loops with arbitrary exit conditions)
Declare fixed-length for loop counts of multiples of 4 or 8 (this avoids the compiler having to produce tail-handling code, i.e., code that handles the odd remaining data items)
Avoid break in loops
Function calls in loops should be inlined where possible
Use simple indexing as indirect addressing can be more difficult for the compiler to vectorize
Large data passed to a function will be passed using pointers. Those functions should be tagged with [NoAlias]. This tells the compiler that no overlaps occur in the pointers and the code is fine to be vectorized.
Don’t try to optimize every line and every function. Focus on the parts of the code that will get the biggest performance gains.
Measure, optimize and check; iteratively make changes, measuring performance before and after to ensure each change is an improvement
Use Hint intrinsics such as Assume, likely, and unlikely. Read about hints in the Burst documentation
Modifications to collision sample to aid auto-vectorization
The following changes were made from the plain code (unoptimized) version:
Install Burst and use
BurstCompileon key functionsCollision detection routines were moved to static Burst functions
Struct data such as AABBs stored as single array of floats
Aggressive inlining was used by applying [MethodImpl(MethodImplOptions.AggressiveInlining)] to key functions
Writing Neon intrinsics
Before diving into the modifications made to optimize for Neon, here are some points to consider when investigating Neon for your own projects:
The Burst compiler optimizes really well on its own but Neon intrinsics can help gain a little bit more performance
Neon intrinsics let you use a high level language while still accessing the low level native instructions you need
The compiler won’t always recognize code that is vectorizable so it’s worth checking what is and isn’t getting vectorized. The Unity Burst Inspector can help you identify which areas of your code are using Burst.
Writing Neon code can be complex
You must use static Burst functions or Jobs. In the sample code, static functions make it easier to measure timings but in a real-world application you may find Jobs provide even better performance, depending on your situation. The sample project provides a Job-based solution which you can experiment with.
You can use
if (IsNeonSupported)to fall back to non-Neon code.IsNeonSupportedhas no runtime overheadNot all Neon intrinsics are supported. Check the Burst documentation .
Neon intrinsics can be used within Burst static functions or Burst Jobs. To use Neon within a static function you simply tag it with the same [BurstCompile] tag we used previously. You will also want to use best practice such as [NoAlias] and unsafe with pointer parameters.
[BurstCompile]
static unsafe void DoSomething([NoAlias] in float* inputs, [NoAlias] float* outputs)
{
... your code ...
}
Modifications made to implement Neon intrinsics in collision sample
Because the Burst compiler did such a good job, further structural changes were only required to really get the most from the Neon intrinsics implementation, and to get a significant improvement over the Burst compiler’s auto-vectorization.
In radius collision detection, we increase simultaneous comparisons to 8
Compare character with 8 walls at once (2 lots of 4)
The sign of some values changed so that all comparisons became a vectorized greater than operation (more on this below)
Wall collision data layout was changed to separate all values into their own array (each wall has four floats (min.x, min.y, max.x, max.y) which were split into 4 arrays)
This diagram shows how we changed from having each wall fill a 4-element vector to separate arrays so each vector holds values from 4 walls.
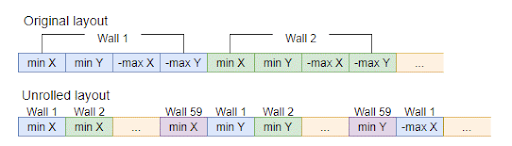
The character-wall collision detection is performed in NeonAABBObjCollisionDetectionUnrolled.
The function loops over all characters and compares each against all the walls. The inner Neon code is performing 4 character-wall comparisons using vectors. The code is repeated (unrolled) to effectively deal with 8 character-wall collision detections per loop iteration.
Each character-wall collision is detected using a vectorized version of the Intersects function of StaticCollisionObject. It is checking if two AABBs overlap. Some changes to the algorithm have been made to make it more suitable for vectorization:
For all characters
{
For number of walls / 8
{
For 4 walls
{
Check collision for wall against character
}
For next 4 walls
{
Check collision for wall against character
}
Combine 8 results and write out to memory
}
}
The AABB intersection function
This function is also slightly modified to be more vectorizable. The sign of some AABB data is flipped so that all of the comparisons use greater than. The algorithm for an individual character-wall collision check then becomes:
bool Intersects(AABB wall, AABB character) {
return !(
wall.MinX > character.MaxX ||
wall.MinY > character.MaxY ||
wall.NegMaxX > character.NegMinX ||
wall.NegMaxY > character.NegMinY
)
}
NOTE. Intersects and AABB do not exist in the code and are only here for illustrative purposes only.
Character-character collision detection
This is left as an exercise for the reader. You may wish to explore the NeonRadiusObjCollisionDetectionUnrolled function starting on line 561 of CollisionCalculationScript.cs.
Additional notes
Here are some general points that you will find useful when you review the sample code and try the concepts in your own projects:
For Burst, and especially for Neon, a lot of the optimization effort will be around the organization of your data. Using structures of arrays over arrays of structures , storing, retrieving and processing data as vectors (grouping similar data that requires the same data operation), and knowing what data is used with what and what data can be stored next to each other.
The sample project increases the character count over time. Because of this, it was better to profile using later frames. In earlier frames there aren’t enough characters so the overhead of vectorization counters any gains.
An early implementation used Burst Jobs. The Jobs got in the way of performance timing because they are not guaranteed to execute immediately. The Job implementations have been left in the code for you to experiment with. Leveraging Jobs in your own projects can lead to important performance gains when used appropriately.
[NoAlias] (explained in best practices ) had a big impact on the performance gains (without it some optimizations produced little to no gain).
The sample code displays some timing data on screen. It used
System.Diagnostics.Stopwatchto get accurate timings.It may sound obvious but don’t use the optimizations when they are slower! For the collision sample, the best gain is when there are lots of characters but earlier on, there aren’t that many so, when there aren’t many characters in the scene, the code could switch to whichever is the fastest version.
The Neon intrinsics we used
For a brief description of some of the Neon intrinsics we used in the collision detection functions, please read the Appendix .