Build a RAG application using Zilliz Cloud on Arm servers
Introduction
Overview and Install dependencies
Offline Data Loading
Launch the LLM Server
Online RAG
Next Steps
Build a RAG application using Zilliz Cloud on Arm servers
Create a dedicated cluster
In this section, you will set up a cluster on Zilliz Cloud.
Begin by registering for a free account on Zilliz Cloud.
After you register, create a cluster .
Now create a Dedicated cluster deployed in AWS using Arm-based machines to store and retrieve the vector data as shown:
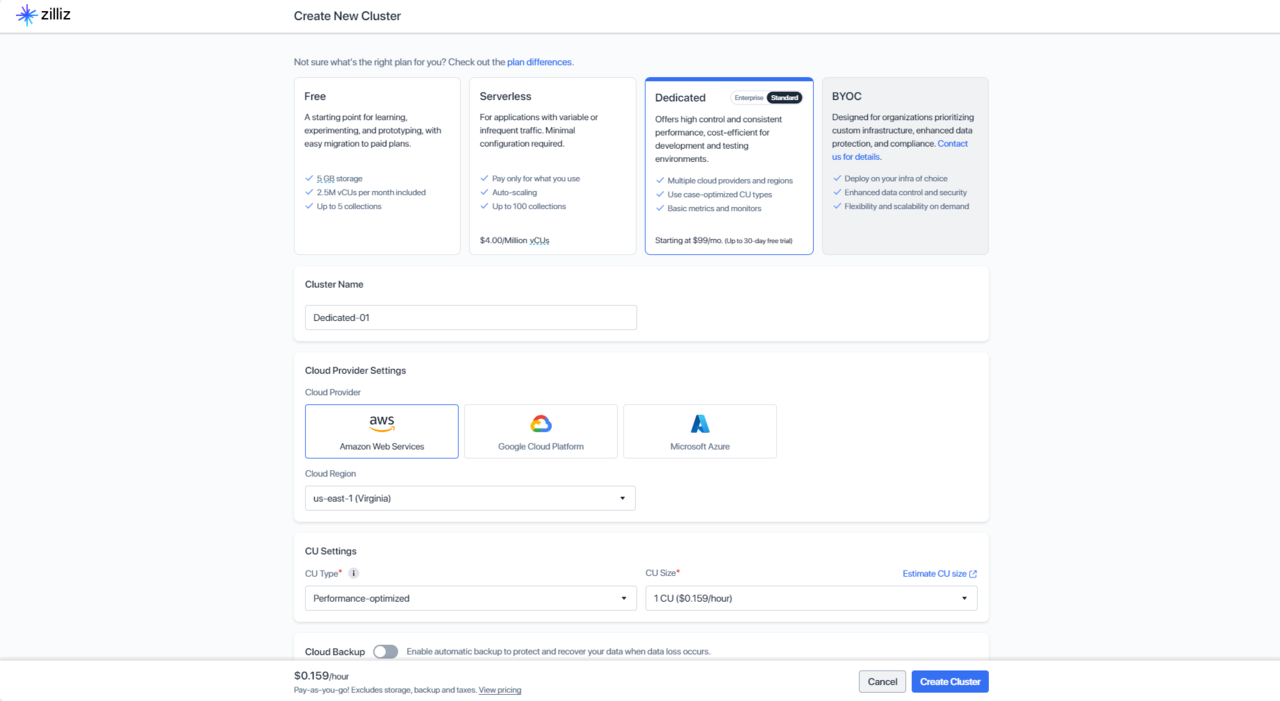
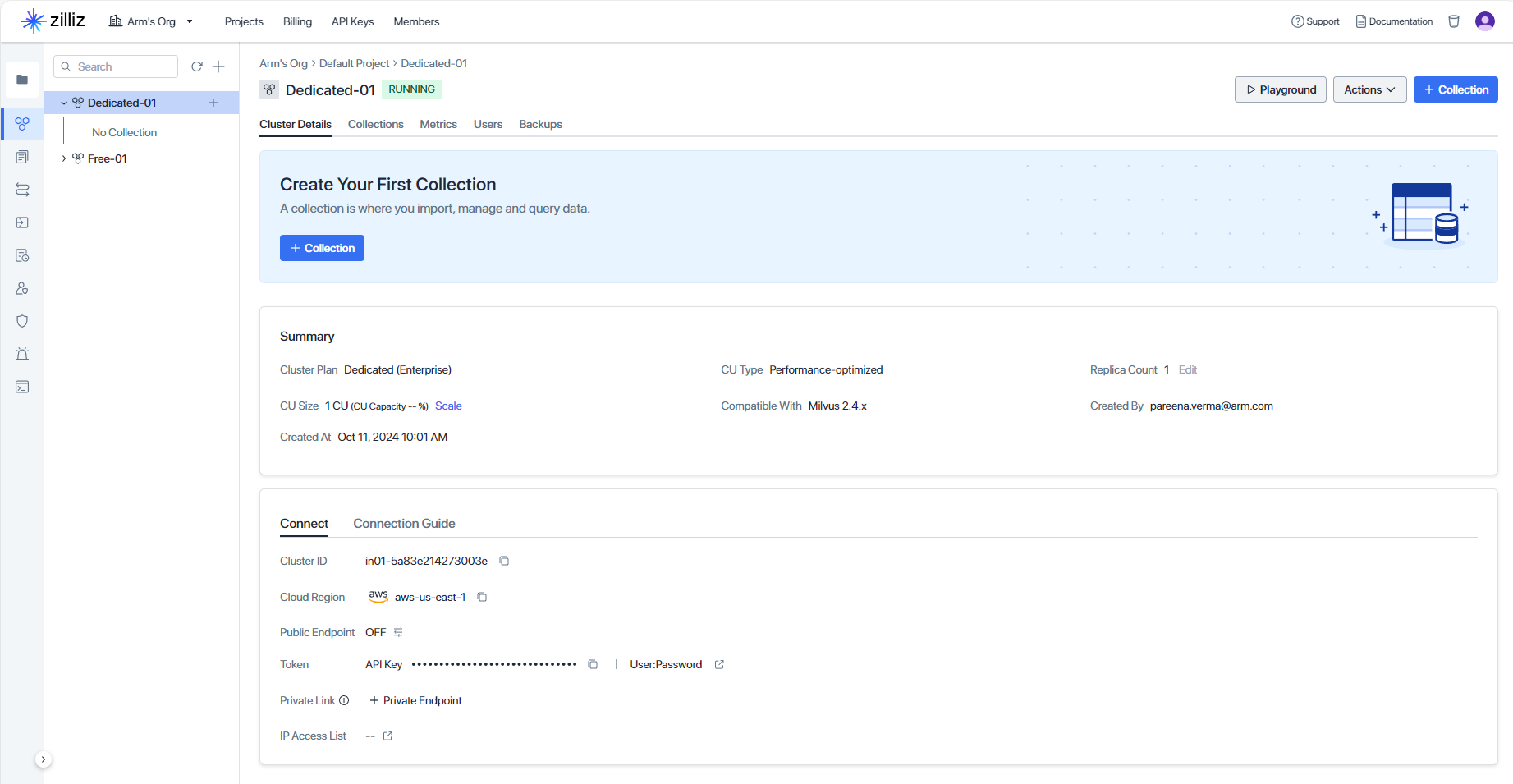
When you select the Create Cluster Button, you should see the cluster running in your Default Project.
You can use self-hosted Milvus as an alternative to Zilliz Cloud. This option is more complicated to set up. You can also deploy Milvus Standalone and Kubernetes on Arm-based machines. For more information about installing Milvus, see the Milvus installation documentation .
Create the Collection
With the Dedicated cluster running in Zilliz Cloud, you are now ready to create a collection in your cluster.
Within your activated Python virtual environment venv, start by creating a file named zilliz-llm-rag.py, and copy the contents below into it:
from pymilvus import MilvusClient
milvus_client = MilvusClient(
uri="<your_zilliz_public_endpoint>", token="<your_zilliz_api_key>"
)
Replace <your_zilliz_public_endpoint> and URI and Token for your running cluster. Refer to
Public Endpoint and Api key
in Zilliz Cloud for further information.
Now, append the following code to zilliz-llm-rag.py and save the contents:
collection_name = "my_rag_collection"
embedding_dim = 384
if milvus_client.has_collection(collection_name):
milvus_client.drop_collection(collection_name)
milvus_client.create_collection(
collection_name=collection_name,
dimension=embedding_dim,
metric_type="IP", # Inner product distance
consistency_level="Strong", # Strong consistency level
)
This code checks if a collection already exists and drops it if it does. If this happens, you can create a new collection with the specified parameters.
If you do not specify any field information, Milvus automatically creates a default id field for the primary key, and a vector field to store the vector data. A reserved JSON field is used to store non-schema defined fields and their values.
You can use inner product distance as the default metric type. For more information about distance types, you can refer to
Similarity Metrics page
.
You can now prepare the data to use in this collection.
Prepare the data
In this example, you will use the FAQ pages from the Milvus Documentation 2.4.x as the private knowledge that is loaded in your RAG dataset.
Download the zip file and extract documents to the folder milvus_docs.
wget https://github.com/milvus-io/milvus-docs/releases/download/v2.4.6-preview/milvus_docs_2.4.x_en.zip
unzip -q milvus_docs_2.4.x_en.zip -d milvus_docs
Now load all the markdown files from the folder milvus_docs/en/faq into your data collection. For each document, use “# " to separate the content in the file. This divides the content of each main part of the markdown file.
Open zilliz-llm-rag.py and append the following code to it:
from glob import glob
text_lines = []
for file_path in glob("milvus_docs/en/faq/*.md", recursive=True):
with open(file_path, "r") as file:
file_text = file.read()
text_lines += file_text.split("# ")
Insert data
Now you can prepare a simple but efficient embedding model all-MiniLM-L6-v2 that can convert the loaded text into embedding vectors.
You can iterate through the text lines, create embeddings, and then insert the data into Milvus.
Append and save the code shown below into zilliz-llm-rag.py:
from langchain_huggingface import HuggingFaceEmbeddings
embedding_model = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
from tqdm import tqdm
data = []
text_embeddings = embedding_model.embed_documents(text_lines)
for i, (line, embedding) in enumerate(
tqdm(zip(text_lines, text_embeddings), desc="Creating embeddings")
):
data.append({"id": i, "vector": embedding, "text": line})
milvus_client.insert(collection_name=collection_name, data=data)
Run the Python script, to check that you have successfully created the embeddings on the data you loaded into the RAG collection:
python3 zilliz-llm-rag.py
The output should look like:
Creating embeddings: 72it [00:00, 700672.59it/s]