Learn about the C++ memory model for porting applications to Arm
Introduction
Introduction to C++ Memory Models
The C++ Memory Model and Atomics
Walk through a Race condition example
Detecting race conditions
Next Steps
Learn about the C++ memory model for porting applications to Arm
Example of a race condition when porting from x86 to Arm
Due to the differences in the hardware memory ordering, as explained in the earlier sections, source code written for x86 can behave differently when ported to Arm.
To demonstrate this, this section walks you through a simple example that is run on both an x86 and an Arm cloud instance.
Get Started
Start an Arm-based cloud instance. This example uses a t4g.xlarge AWS instance running Ubuntu 22.04 LTS, but you can use other instance types.
If you are new to cloud-based virtual machines, see Get started with Servers and Cloud Computing .
First, confirm you are using a Arm-based instance with the following command.
uname -m
You should see the following output:
aarch64
Next, install the required software packages:
sudo apt update
sudo apt install g++ clang -y
Use a text editor to copy and paste the following code snippet into a file named relaxed_memory_ordering.cpp:
#include <iostream>
#include <atomic>
#include <thread>
#include <cassert>
#include <chrono>
struct Node {
int x;
};
std::atomic<Node*> node{nullptr};
void threadA() {
auto n = new Node();
n->x = 42;
node.store(n, std::memory_order_relaxed);
}
void threadB() {
Node* n = nullptr;
while ((n = node.load(std::memory_order_relaxed)) == nullptr) {
std::this_thread::sleep_for(std::chrono::nanoseconds(50)); // Small sleep to improve scheduling
}
if (n->x != 42) {
std::cerr << "Race condition detected: n->x = " << n->x << std::endl;
std::terminate();
}
}
void runTest() {
for (int i = 0; i < 100000; ++i) { // Run many iterations but eventually time out
node.store(nullptr, std::memory_order_relaxed);
std::thread t1(threadA);
std::thread t2(threadB);
std::thread t3(threadA);
std::thread t4(threadA);
t1.join();
t2.join();
t3.join();
t4.join();
delete node.load();
}
}
int main() {
runTest();
std::cout << "No Race Condition Occurred in this run" << std::endl;
return 0;
}
The code above demonstrates a data race condition. Thread A creates a node variable and assigns it the value 42. Thread B checks that the variable assigned to the Node equals 42. Both threads use memory_order_relaxed model, allowing thread B to potentially read an uninitialized variable before thread A assigns the value of 42.
Compile the program using the GNU compiler:
g++ relaxed_memory_ordering.cpp -o relaxed_memory_ordering -O3
Run the binary 10 times to increase the chance of observing a race condition:
for i in {1..10}; do ./relaxed_memory_ordering; done;
If you do not see a race condition, the animation below shows a race condition being triggered on the third run:
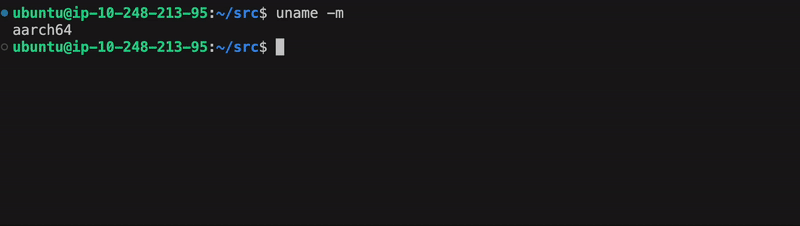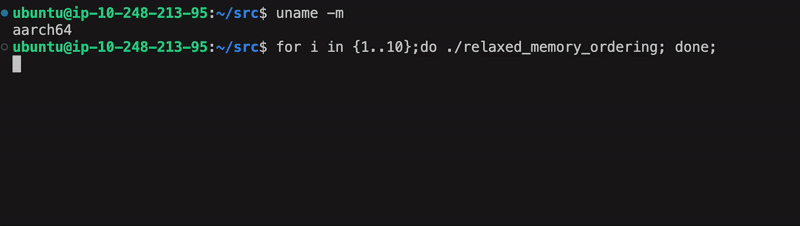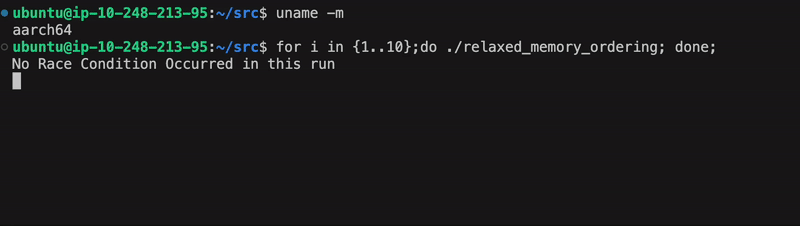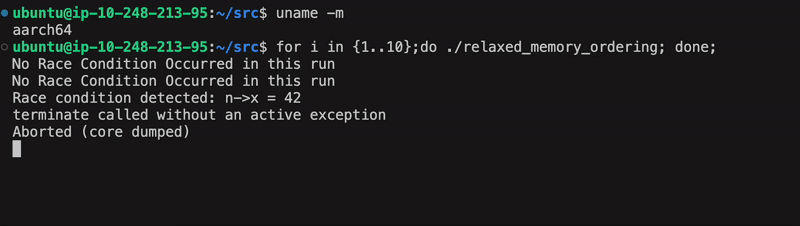
As the graphic above illustrates, a race condition is probabilistic, and not guaranteed.
Subtle issues can surface under specific workloads, making them challenging to detect.
Behavior on an x86 instance
Due to the stronger memory model in x86 processors, programs not adhering to the C++ standard might give programmers a false sense of security. To demonstrate this, create an connect to an AWS t2.2xlarge instance that uses the x86 architecture.
Running the command below you observe the underlying hardware is a Intel Xeon E5-2686 Processor.
lscpu | grep -i "Model"
Here is the output:
Model name: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz
Model: 79
Follow the same instructions to compile and run the application.
g++ relaxed_memory_ordering.cpp -o relaxed_memory_ordering -O3
./relaxed_memory_ordering
Observe there is no race conditions on the x86-based machine.
The output is:
No race condition occurred in this run
Using correct memory ordering of atomics
As the example above shows, not adhering to the C++ standard can lead to a false sensitivity when running on x86 platforms. To fix the race condition when porting you need to use the correct memory ordering for each thread. The code below updates threadA to use the memory_order_release, threadB to use memory_order_acquire and the runTest function to use memory_order_release on the Node object.
Use an editor to copy and past the adjusted code below into a file named correct_memory_ordering.cpp.
#include <iostream>
#include <atomic>
#include <thread>
#include <cassert>
#include <chrono>
struct Node {
int x;
};
std::atomic<Node*> node{nullptr};
void threadA() {
auto n = new Node();
n->x = 42;
node.store(n, std::memory_order_release);
}
void threadB() {
Node* n = nullptr;
while ((n = node.load(std::memory_order_acquire)) == nullptr) {
std::this_thread::sleep_for(std::chrono::nanoseconds(50)); // Small sleep to improve scheduling
}
if (n->x != 42) {
std::cerr << "Race condition detected: n->x = " << n->x << std::endl;
std::terminate();
}
}
void runTest() {
for (int i = 0; i < 100000; ++i) { // Run many iterations but eventually time out
node.store(nullptr, std::memory_order_release);
std::thread t1(threadA);
std::thread t2(threadB);
std::thread t3(threadA);
std::thread t4(threadA);
t1.join();
t2.join();
t3.join();
t4.join();
delete node.load();
}
}
int main() {
runTest();
std::cout << "No Race Condition Occurred in this run" << std::endl;
return 0;
}
Compile and run the new code on the Arm-based machine:
g++ correct_memory_ordering.cpp -o correct_memory_ordering -O3
./correct_memory_ordering
Observe the race condition is gone and the output is:
No Race Condition Occurred in this run