Explore floating-point differences between x86 and Arm
Introduction
Floating-Point Representation
Differences between x86 and Arm
Error propagation
Minimizing floating-point variability across platforms
Next Steps
Explore floating-point differences between x86 and Arm
What are the differences in behavior between x86 and Arm floating point?
Although both x86 and Arm generally follow the IEEE 754 standard for floating-point representation, their behavior in edge cases — like overflow and truncation — can differ due to implementation details and instruction sets.
You can see this by comparing an example application on both an x86 and an Arm Linux system.
Run this example on any Linux system with x86 and Arm architecture; on AWS, use EC2 instance types t3.micro and t4g.small with Ubuntu 24.04.
To learn about floating-point differences, use an editor to copy and paste the C++ code below into a new file named converting-float.cpp:
#include <iostream>
#include <cmath>
#include <limits>
#include <cstdint>
void convertFloatToInt(float value) {
// Convert to unsigned 32-bit integer
uint32_t u32 = static_cast<uint32_t>(value);
// Convert to signed 32-bit integer
int32_t s32 = static_cast<int32_t>(value);
// Convert to unsigned 16-bit integer (truncation happens)
uint16_t u16 = static_cast<uint16_t>(u32);
uint8_t u8 = static_cast<uint8_t>(value);
// Convert to signed 16-bit integer (truncation happens)
int16_t s16 = static_cast<int16_t>(s32);
std::cout << "Floating-Point Value: " << value << "\n";
std::cout << " → uint32_t: " << u32 << " (0x" << std::hex << u32 << std::dec << ")\n";
std::cout << " → int32_t: " << s32 << " (0x" << std::hex << s32 << std::dec << ")\n";
std::cout << " → uint16_t (truncated): " << u16 << " (0x" << std::hex << u16 << std::dec << ")\n";
std::cout << " → int16_t (truncated): " << s16 << " (0x" << std::hex << s16 << std::dec << ")\n";
std::cout << " → uint8_t (truncated): " << static_cast<int>(u8) << std::endl;
std::cout << "----------------------------------\n";
}
int main() {
std::cout << "Demonstrating Floating-Point to Integer Conversion\n\n";
// Test cases
convertFloatToInt(42.7f); // Normal case
convertFloatToInt(-15.3f); // Negative value -> wraps on unsigned
convertFloatToInt(4294967296.0f); // Overflow: 2^32 (UINT32_MAX + 1)
convertFloatToInt(3.4e+38f); // Large float exceeding UINT32_MAX
convertFloatToInt(-3.4e+38f); // Large negative float
convertFloatToInt(NAN); // NaN behavior on different platforms
return 0;
}
If you need to install the g++ compiler, run the commands below:
sudo apt update
sudo apt install g++ -y
Compile converting-float.cpp on an Arm and x86 machine.
The compile command is the same on both systems.
g++ converting-float.cpp -o converting-float
For easy comparison, the image below shows the x86 output (left) and Arm output (right). The highlighted lines show the difference in output:
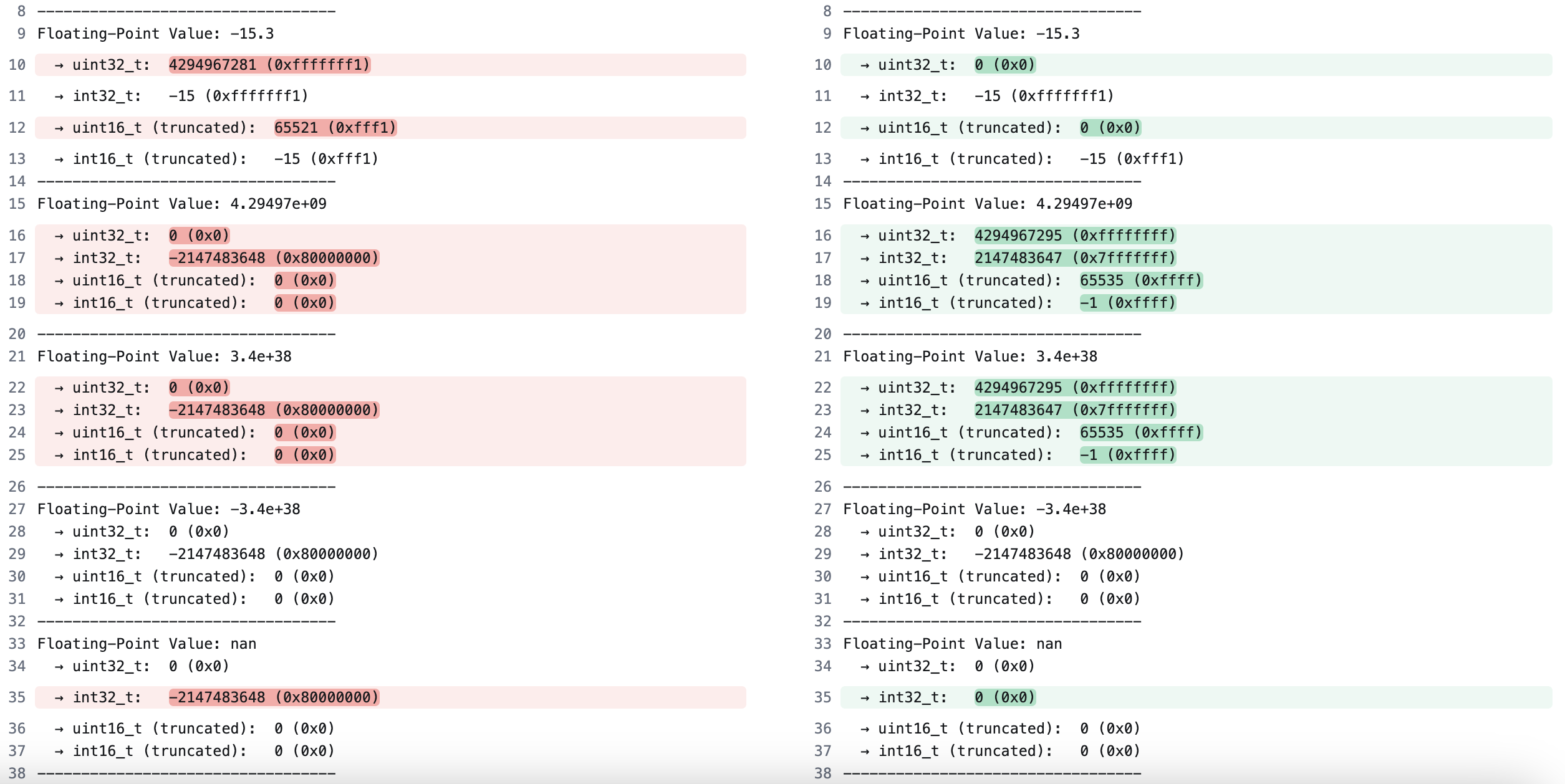
As you can see, there are several cases where different behavior is observed. For example when trying to convert a signed number to an unsigned number or dealing with out-of-bounds numbers.
Removing hardcoded values with macros
The above differences show that explicitly checking for specific values will lead to unportable code.
For example, the function below checks if the casted result is 0. This can be misleading — on x86, casting an out-of-range floating-point value to uint32_t may wrap to 0, while on Arm it may behave differently. Relying on these results makes the code unportable.
void checkFloatToUint32(float num) {
uint32_t castedNum = static_cast<uint32_t>(num);
if (castedNum == 0) {
std::cout << "The casted number is 0, indicating that the float is out of bounds for uint32_t." << std::endl;
} else {
std::cout << "The casted number is: " << castedNum << std::endl;
}
}
This can simply be corrected by using the macro, UINT32_MAX.
To find out all the available compiler-defined macros, you can output them using:
echo "" | g++ -dM -E -
A portable version of the code is:
void checkFloatToUint32(float num) {
uint32_t castedNum = static_cast<uint32_t>(num);
if (castedNum == UINT32_MAX) {
std::cout << "The casted number is " << UINT32_MAX << " indicating the float was out of bounds for uint32_t." << std::endl;
} else {
std::cout << "The casted number is: " << castedNum << std::endl;
}
}